第二章
第二章 应用层
2.1 应用层原理
创建一个新的网络应用
编程
- 在不同的端系统上运行
- 通过网络基础设施提供的服务,应用进程彼此通信
- 如Web:Web服务器软件与浏览器软件通信
网络核心中没有应用层软件
- 网络核心没有应用层功能
- 网络应用只在端系统上存在,快速网络应用开发和部署
网络应用的体系架构
可能的应用架构:
- 客户-服务器模式(C/S: client/server)
- 对等模式(P2P: Peer To Peer)
- 混合体: 客户-服务器和对等体系结构
客户-服务器(C/S) 体系结构
服务器:
- 一直运行
- 固定的IP地址和周知的端口号(约定)
- 扩展性:服务器场
- 数据中心进行扩展
- 扩展性差
客户端:
- 主动与服务器通信
- 与互联网有间歇性的连接
- 可能是动态IP地址
- 不直接与其他客户端通信
对等体(P2P)体系结构
- (几乎)没有一直运行的服务器
- 任意端系统之间可以进行通信
- 每一个节点既是客户端又是服务器
- 自扩展性-新peer节点带来新的服务能力,当然也带来新的服务请求
- 参与的主机间歇性连接且可以改变IP地址
- 难以管理
- 例子:Gnutella,迅雷
C/S和P2P体系结构的混合体
Napster
- 文件搜索:集中
- 主机在中心服务器上注册其资源
- 主机向中心服务器查询资源位置
- 文件传输:P2P
- 任意Peer节点之间
即时通信
- 在线检测:集中
- 当用户上线时,向中心服务器注册其IP地址
- 用户与中心服务器联系,以找到其在线好友的位置
- 两个用户之间聊天:P2P
进程通信
进程:在主机上运行的应用程序
- 在同一个主机内,使用进程间通信机制通信(操作系统定义)
- 不同主机,通过交换报文(Message)来通信
- 使用OS提供的通信服务(如管道,消息队列,共享缓冲区)
- 按照应用协议交换报文—借助传输层提供的服务
- 注意: P2P架构的应用也有客户端进程和服务器进程之分
客户端进程:发起通信的进程
服务器进程:等待连接的进程
分布式进程通信需要解决的问题
- 进程标示和寻址问题(服务用户)
- 传输层-应用层提供服务是如何(服务)
- 位置:层间界面的SAP(TCP/IP:socket)
- 形式:应用程序接口API(TCP/IP:socket API)
- 如何使用传输层提供的服务,实现应用进程之间的报文交换,实现应用(用户使用服务)
- 定义应用层协议:报文格式,解释,时序等
- 编制程序,使用OS提供的API,调用网络基础设施提供通信服务传报文,实现应用时序等
问题1:对进程进行编制(addressing)
- 进程为了接受报文,必须有一个标示,即:SAP(发送也需要标示)
- 主机:唯一的32位IP地址—仅仅有IP地址不能够唯一标示一个进程:在一台端系统上有很多应用进程在运行
- 所采用的传输层协议:TCP or UDP
- 端口号(Port Numbers)
- 一些知名端口号
- HTTP:TCP 80
- Mail:TCP 25
- ftp:TCP 2
- 一个进程:用IP+port标示端节点(如果多个进程争抢同一端口?—socket不仅包含端口信息,其实是一种对话关系,B可以同时和A,和C在xx端口建立通信,同一端口可以复用,但注意socket所代表的四元组不能完全相同)
- 本质上,一对主机进程之间的通信由2个端节点(end point)构成
问题2:传输层提供的服务-需要穿过层间的信息
- 层间接口必须要携带的信息
- 要传输的报文(对于本层来说:SDU)
- 谁传的:对方的应用进程的标示:IP+TCP(UDP)端口
- 传给谁:对方的应用进程的标示:对方的IP+TCP(UDP)端口
- 传输层实体(tcp或者udp实体)根据这些信息进行TCP报文段(UDP数据报)的封装
- 源端口号,目标端口号,数据等
- 将IP地址往下交IP实体,用于封装IP数据报:源IP,目标IP
问题2:传输层提供的服务-层间信息的代表
- 如果Socket API每次传输报文,都携带如此多的信息,太繁杂易错,不便于管理
- 用个代号标示通信的双方或者单方:socket
- 就像OS打开文件返回的句柄一样—对句柄的操作,就是对文件的操作
- TCP socket:
- TCP服务,两个进程之间的通信需要之前要建立连接—两个进程通信会持续一段时间,通信关系稳定
- 可以用一个整数表示两个应用实体之间的通信关系,本地标示
- 穿过层间接口的信息量最小(原本至少要传4个字符串参数,现在只用传一个整数参数)
- TCP socket:源IP,源端口,目标IP,目标端口
TCP之上的套接字(socket)
对于使用面向连接服务(TCP)的应用而言,套接字是4元组的一个具有本地意义的标示
- 4元组:(源IP,源port,目标IP,目标port)
- 唯一的指定了一个会话(2个进程之间的会话关系)
- 应用使用这个标标示,与远程的应用进程通信
- 不必在每一个报文的发送都要指定这4元组
- 就像使用操作系统打开一个文件,OS返回一个文件句柄一样,以后使用这个文件句柄,而不是使用这个文件的目录名,文件名(因此压缩传过层间接口的信息量)
- 简单,便于管理
UDP socket:
- UDP服务,两个进程之间的通信需要之前无需建立连接
- 每个报文都是独立传输的
- 前后报文可能给不同的分布式进程
- 因此,只能用一个整数表示本应用实体的标示
- 因为这个报文可能传给另外一个分布式进程
- 穿过层间接口的信息大小最小
- UDP socket:本IP,本端口
- 但是传输报文时,必须要提供对方IP,port
- 接受报文时:传输层需要上传对方的IP,port
UDP之上的套接字(socket)
对于使用无连接服务(UDP)的应用而言,套接字是2元组的一个具有本地意义的标示
- 2元组:IP, port(源端指定)
- UDP套接字指定了应用所在的一个端节点(end point)
- 在发送数据报时,采用创建好的本地套接字(标示ID),就不必在发送每个报文中指明自己所采用的ip和port
- 但是在发送报文时,必须要指定对方的ip和udp port(另外一个端节点)
问题3:如何使用传输层提供的服务实现应用
- 定义应用层协议:报文格式,解释,时序等
- 编制程序,通过API调用网络基础设施提供通信服务传报文,解析报文,实现应用时序等
应用层协议
- 定义了:运行在不同端系统上的应用进程如何相互交换报文
- 交换的报文类型:请求和应答报文
- 各种报文类型的语法:报文中的各个字段及其描述
- 字段的语义:即字段取值的含义
- 进程何时,如何发送报文及对报文进行响应的规则
- 应用协议仅仅是应用的一个组成部分
- Web应用:HTTP协议,web客户端,web服务器,HTML
- 公开协议:
- 由RFC文档定义
- 允许互操作
- 如HTTP,SMTP
- 专用(私有协议):
- 协议不公开
- 如:Skype
应用需要传输层提供什么样的服务?
- 数据丢失率
- 有些应用要求100%的可靠数据传输(如文件)
- 有些应用(如音频)能容忍一定比例以下的数据丢失
- 延迟
- 一些应用出于有效性考虑,对数据传输有严格的时间限制
- Internet电话,交互式游戏
- 延迟,延迟差
- 一些应用出于有效性考虑,对数据传输有严格的时间限制
- 吞吐
- 一些应用(如多媒体)必须需要最小限度的吞吐,从而使得应用能够有效运转
- 一些应用能充分利用可供使用的吞吐(弹性应用)
- 安全性
- 机密性
- 完整性
- 可认证性(鉴别)

(视频应为100kbps~5Mbps)
Internet传输层提供的服务

UDP存在的必要性
- 能够区分不同的进程,而IP服务不同(在IP提供的主机到主机端到端的基础上,区分了主机的应用进程)
- 无需建立连接,省去了建立连接时间,适合事务性的应用
- 不做可靠性的工作,例如检错重发,适合那些对实时性要求比较高而对正确性要求不高的应用—因为为了实现可靠性(准确性,保序等),必须付出时间代价(检错重发)
- 没有拥塞控制和流量控制,应用能够按照设定的速度发送数据—而在TCP上的应用,应用发送数据的速度和主机向网络发送的实际速度是不一致的,因为有流量控制和拥塞控制
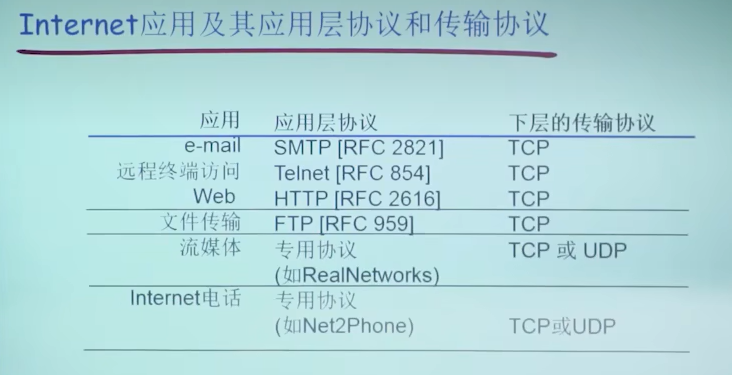
Internet应用及其应用层协议和传输协议
安全性
TCP&UDP
- 都没有加密
- 明文通过互联网传输,甚至密码
SSL
- 在TCP上面实现,提供加密的TCP连接
- 私密性
- 数据完整性
- 端到端的鉴别
SSL在应用层
- 应用采用SSL库,SSL库使用TCP通信
SSL socket API
- 应用通过API将明文交给socket,SSL将其加密在互联网上传输
- 详见第8章
2.2 Web and HTTP
一些术语:
- Web页:由一些对象组成
- 对象可以是HTML文件,JPEG图像,Java小程序,声音剪辑文件等
- Web页含有一个基本的HTML文件,该基本HTML文件又包含若干对象的引用(链接)
- 通过URL(通用资源定位符)对每个对象进行引用
- 访问协议,用户名,口令字,端口等
- URL格式:

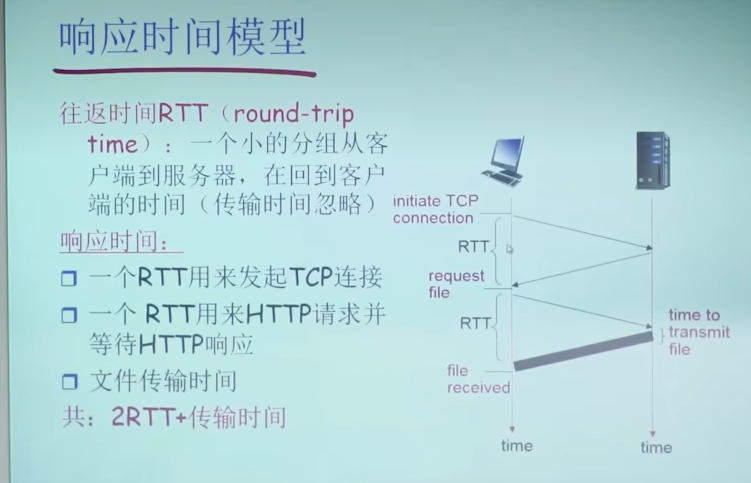
HTTP概况


服务器存在一个等待socket负责在80端口监听连接请求
完成一次请求响应后,对应socket即关闭(如请求html页面,浏览器获得html文件后即关闭socket)
HTTP连接
- 非持久HTTP
- 最多只有一个对象在TCP连接上发送(对象传输完成后,socket即关闭)
- 下载多个对象需要多个TCP连接
- HTTP/1.0使用非持久连接
- 持久HTTP
- 多个对象可以在一个(在客户端和服务器之间的)TCP连接上传输(对象传输完成后,客户端仍可发送http请求,请求下个对象)
- HTTP/1.1默认使用持久连接



流水方式的持久HTTP:前一个对象还没返回时,就请求下一个对象(节省时间)
HTTP请求报文

- GET:请求文件
- POST:上载文件
- HEAD:只请求html的头信息(如搜索引擎建索引)
- Host:主机
- Connection:响应后是否关闭socket
首部行之后可能还包含一些实体行(如post中上载的文件)
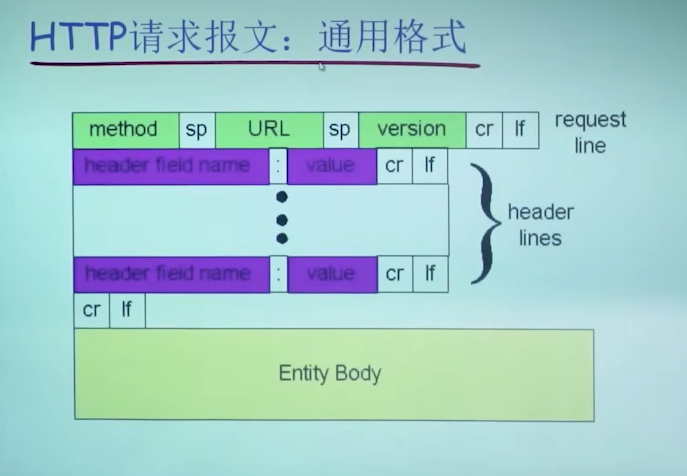
- sp:space 空格
- cr lf :换行
提交表单输入
Post方式:
- 网页通常包括表单输入
- 包含在实体主体(entity body)中的输入被提交到服务器
URL方式:
- 方法:GET
- 输入通过请求行的URL字段上载(在URL中添加对应参数)
方法类型
HTTP/1.0:
- GET
- POST
- HEAD
- 要求服务器在响应报文中不包含对象请求—故障跟踪
- 搜索引擎建立索引
HTTP/1.1:
- GET,POST,HEAD
- PUT
- 将实体主体中的文件上载到URL字段规定的路径
- DELETE
- 删除URL字段规定的文件
HTTP响应报文

- Content-Length:TCP协议本身不维护报文与报文之间的边界(如两个15k的报文可能会被看成一个30k的报文),故HTTP协议需要该参数,判断本报文要读取多少行
HTTP响应状态码

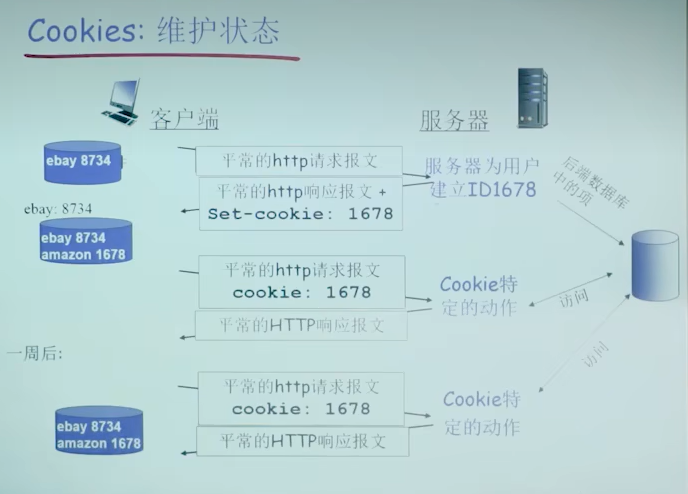
用户-服务器状态:cookies
大多数主要的门户网站使用cookies
4个组成部分:
- 在HTTP响应报文中有一个cookie的首部行
- 在HTTP请求报文含有一个cookie的首部行
- 在用户端系统中保留有一个cookie文件,由用户的浏览器管理
- 在Web站点有一个后端数据库
例子:
- Susan总是用同一个PC使用Internet Explore上网
- 她第一层访问了一个使用了Cookie的电子商务网站
- 当最初的HTTP请求到达服务器时,该Web站点产生一个唯一的ID,并以此作为索引在它的后端数据库中产生一个项

Web缓存(代理服务器/proxy server)
目标:不访问原始服务器,就满足客户的请求
- 用户设置浏览器: 通过缓存访问Web
- 浏览器将所有的HTTP请求发给缓存
- 在缓存中的对象:缓存直接返回对象
- 如对象不在缓存,缓存请求原始服务器,然后再将对象返回给客户端
好处:
- 对客户端来说,不需要每次访问原始服务器(origin server),更快了
- 对服务器来说,减轻了服务器的负载,网络负担轻

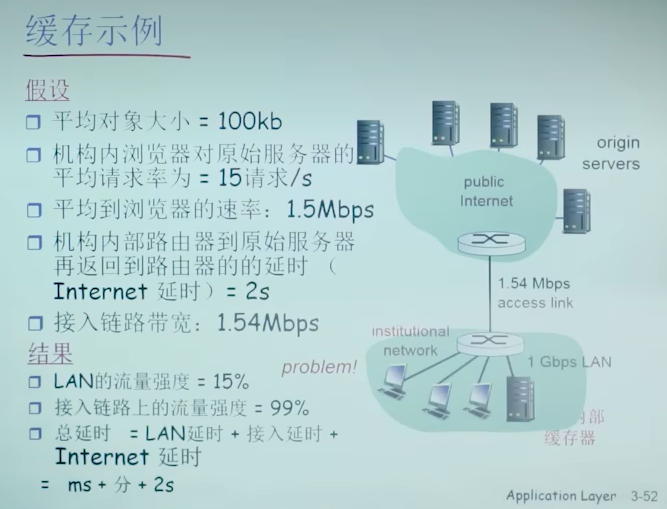
排队时间=I/(1-I)*L/R
解决方案:
- 提高带宽—花销大
- 安装本地缓存
缓存例子:安装本地缓存
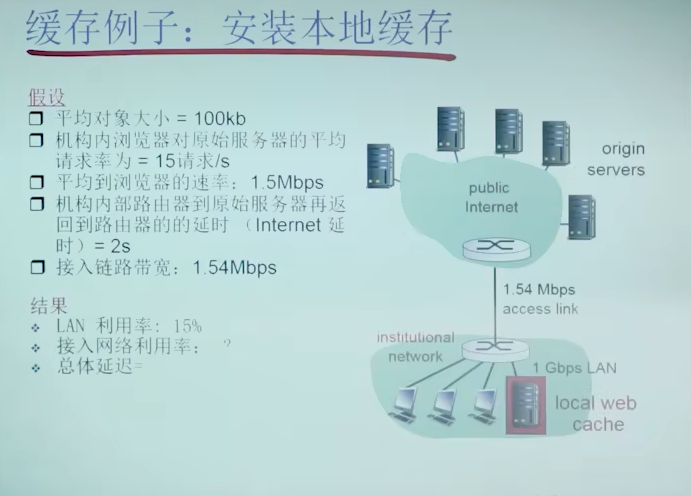
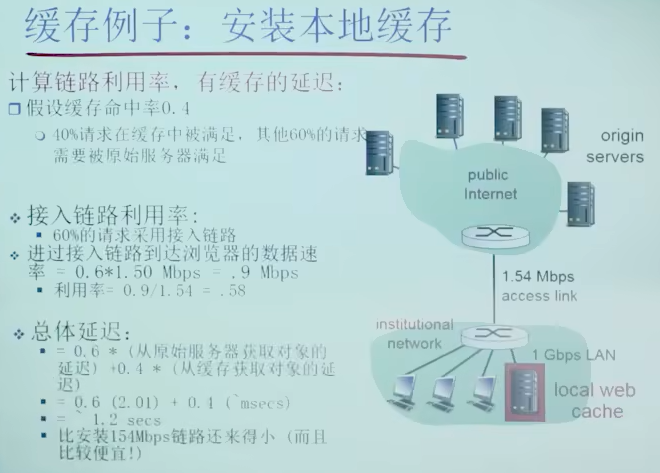
即增加本地缓存,可以减少流量强度,进而大幅减小接入链路的排队时间
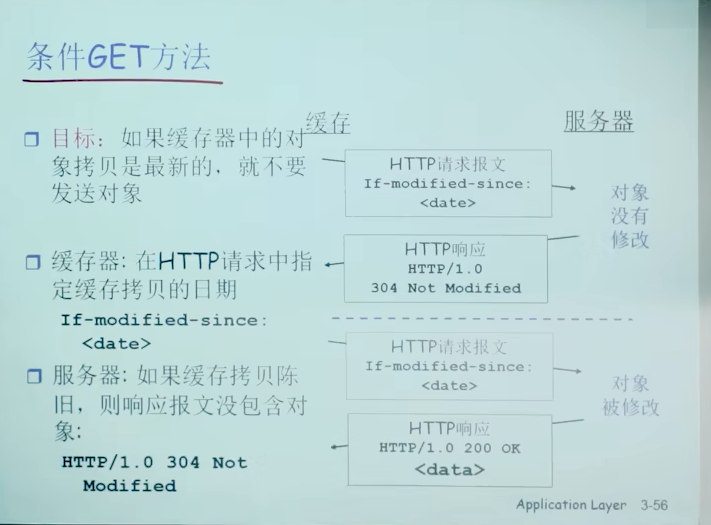
2.3 FTP
FTP:文件传输协议
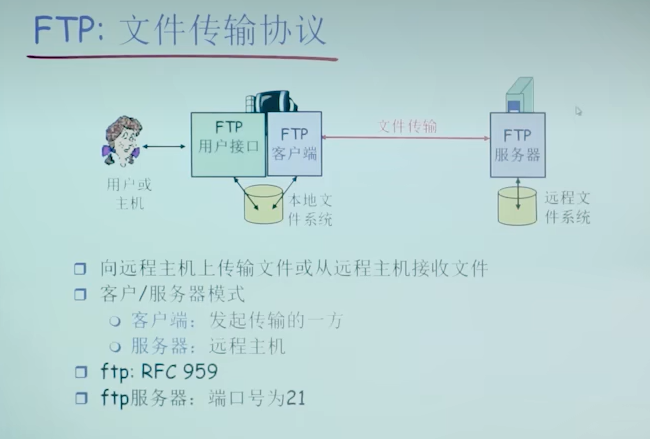
FTP:控制连接与数据连接分开

- FTP客户端与FTP服务器通过端口21联系,并使用TCP为传输协议
- 客户端通过控制连接获得身份确认(甚至因为ftp太老,身份认证是明文传输)
- 客户端通过控制连接发送命令,浏览远程目录
- 收到一个文件传输命令时,服务器打开一个到客户端的数据连接(注意是服务器主动开启)
- 一个文件传输完成后,服务器关闭连接
- 服务器打开第二个TCP数据连接用来传输另一个文件
- 控制连接:带外(“out of band”)传送(带内为数据传输)
- FTP服务器维护用户的状态信息:当前路径,用户账户与控制连接对应
- 有状态
FTP命令,响应

2.4 Email
3个主要组成部分:
- 用户代理
- 邮件服务器
- 简单邮件传输协议:SMTP
用户代理
- 又名”邮件阅读器”
- 撰写,编辑和阅读邮件
- 如Outlook,Foxmail(正如浏览器是Web应用的用户代理)
- 输出和输入邮件保存在服务器上
邮件服务器
- 邮箱中管理和维护发送给用户的邮件
- 输出报文队列保持待发送邮件报文
- 邮件服务器之间的SMTP协议:发送email报文
- 客户:发送方邮件服务器
- 服务器:接受端邮件服务器
- 用户将邮件发到邮件服务器,邮件服务器将其保存在队列中,挨个发送到对应的邮件服务器,服务器收到后,放到对应客户的mailbox中,用户代理查看邮箱时,就从对应服务器中拉取对应邮件(注意这一步采取的不是SMTP协议)
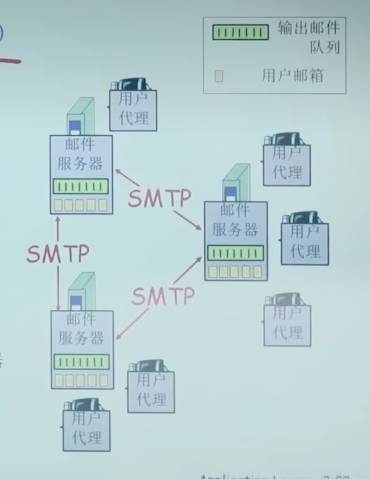
Email: SMTP[RFC 2821]

eg:
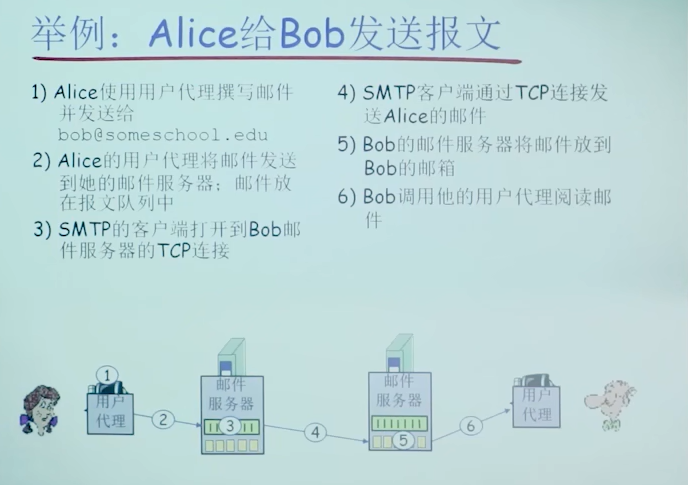

注意:如果后续这俩个服务器之间仍有要发送的邮件,则连接不断开,继续传输
SMTP:总结
- SMTP使用持久连接
- SMTP要求报文(首部和主体)为7位ASCII编码(最高位要为0)
- SMTP服务器使用CRLF.CRLF决定报文的尾部
HTTP比较
- HTTP:拉(pull)
- SMTP:推(push)
- 二者都是ASCII形式的命令/响应交换,状态码
- HTTP:每个对象封装在各自的响应报文中(如HTML中的其他对象)
- SMTP:多个对象包含在一个报文中
邮件报文格式

Base64:将若干个不在ASCII码范围内的字节,转化成更长的,在ASCII码范围内的字节
邮件访问协议
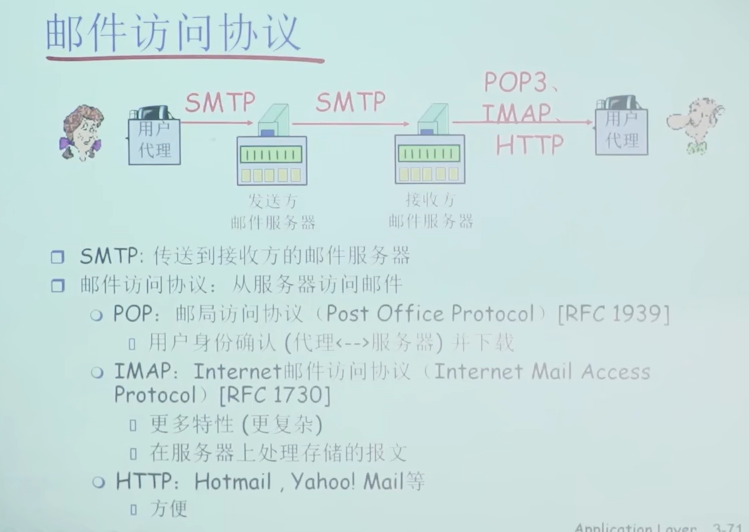
POP3协议

(S的第二次message大概是message2,此处应该是打错了)

2.5 DNS(Domain Name System)
DNS(域名转换系统)的必要性
- IP地址标识主机,路由器
- 但IP地址不好记忆,不便于人类使用(没有意义,ipv4:32bit ipv6:128bit,一般用点分十进制的方法简化)
- 人类一般倾向于使用一些有意义的字符串来标识Internet上的设备
- 存在着”字符串”-IP地址的转换的必要性
- 人类用户提供要访问机器的”字符串”名称
- 由DNS负责转换成为二进制的网络地址
- Web应用,FTP均有利用DNS
DNS系统需要解决的问题
- 如何命名设备
- 用有意义的字符串:好记,便于人类使用
- 解决一个平面命名的重名问题:层次化命名
- 如何完成名字到IP地址的转换
- 分布式的数据库维护和响应名字查询
- 如何维护:增加或者删除一个域,需要在域名系统中做哪些工作
DNS的历史

DNS总体思路和目标
DNS的主要思路
- 分层的,基于域的命名机制
- 若干分布式的数据库完成名字到IP地址的转换
- 运行在UDP之上端口号为53的应用服务
- 核心的Internet功能,但以应用层协议实现—在网络边缘处理复杂性
DNS的目标
- 主要目的:实现主机名-IP地址的转换(name/IP translate)
- 其他目的:
- 主机别名到规范名字的转换:Host aliasing
- 邮件服务器别名到邮件服务器的正规名字的转换:Mail server aliasing(别名是为了方便用户访问,规范名字是为了方便管理,别名—>正规名字—>IP地址)
- 负载均衡:Load Distribution
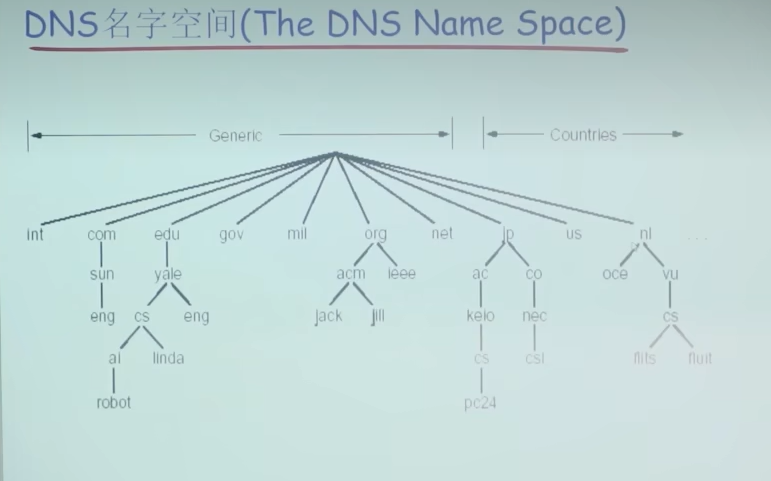
问题1:DNS名字空间(The DNS Name Space)
DNS域名结构
- 一个层面命名设备会有很多重名
- DNS采用层次树状结构的命名方法
- Internet根被划为几百个顶级域(top lever domains)
- 通用的(generic): .com;.edu; .int; .mil; .net; .org; .firm; .hsop; .web; .arts; .rec;
- 国家的(countries): .cn; ,us; .nl; .jp
- 每个(子)域下面可划分为若干子域(subdomains)
- 树叶是主机

域名的管理
- 一个域管理其下的子域
- .jp 被划分为ac.jp co.jp
- .cn被划分为edu.cn com.cn
- 创建一个新的域,必须征得它所属域的同意
域与物理网络无关
- 域遵从组织界限,而不是物理网络
- 一个域的主机可以不在一个网络
- 一个网络的主机不一定在一个域
- 域的划分是逻辑的,而不是物理的
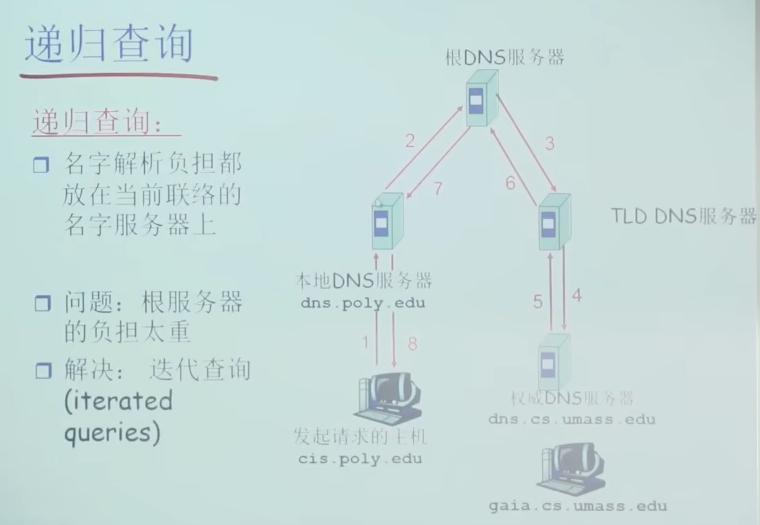
问题2: 解析问题-名字服务器(Name Server)
一个名字服务器的问题
- 可靠性问题:单点故障
- 扩展性问题:通信容量
- 维护问题:远距离的集中式数据库
区域(zone)
- 区域的划分有区域管理者自己决定
- 将DNS名字空间划分为互不相交的区域,每个区域都是树的一部分
- 名字服务器:
- 每个区域都有一个名字服务器:维护着它所管辖区域的权威信息(authoritative record)
- 名字服务器允许被放置在区域之外,以保障可靠性
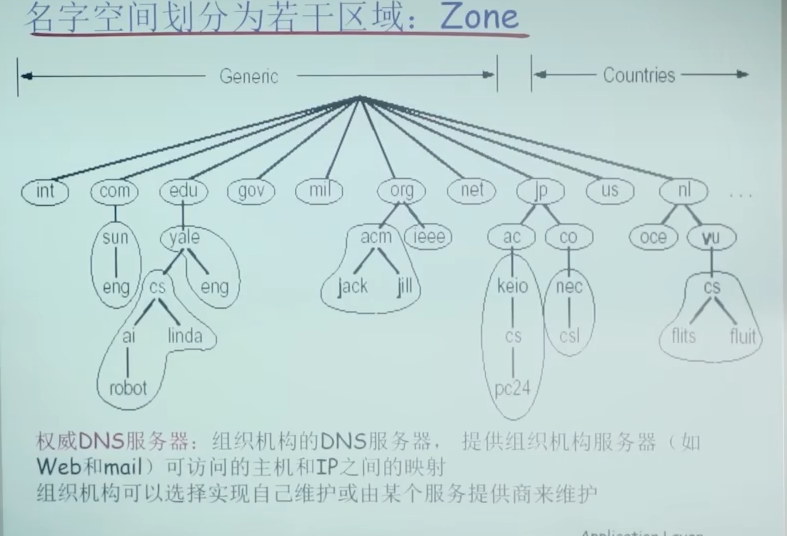
(上层的域服务器都知道其下层的域服务器和对应的IP地址)
TLD服务器:顶级域(TLD)服务器,负责顶级域名(如com,org,net,edu和gov)和所有国家级的顶级域名(如cn,uk,fr,ca,jp)
- Network solutions 公司维护com TLD服务器
- Educause 公司维护edu TLD服务器
区域名字服务器维护资源记录
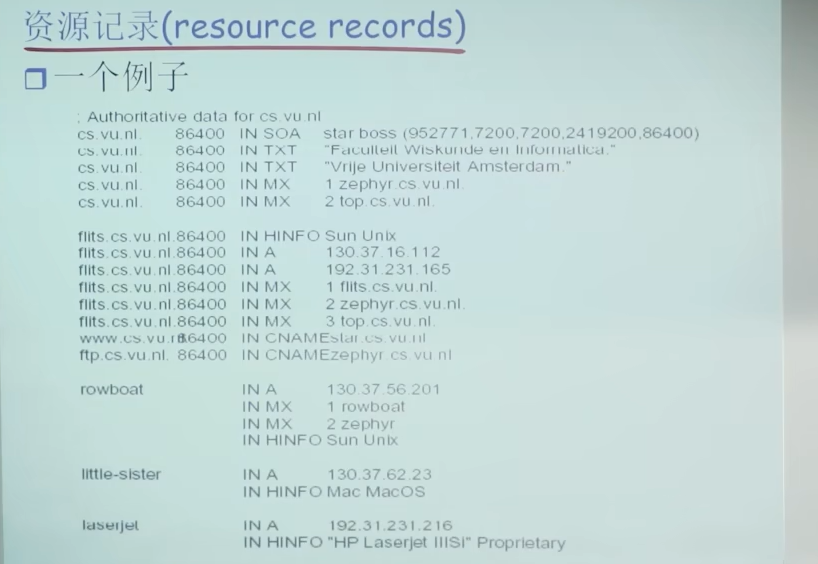
资源记录(resource records)
- 作用: 维护 域名-IP地址的映射关系(还有其他映射关系,比如别名到规范名字的映射关系)
- 位置:Name Server的分布式数据库中
RR格式:(domain_name,ttl,type,class,Value)
- Domain_name: 域名
- ttl(time to live):生存时间(如果ttl无限大,即为权威记录,如果是一个有限值,即为缓冲记录,一段时间后即删去)
- Class类别: 对于Internet,值为IN
- Value值: 可以是数字,域名或ASCII串(即域名所映射的对象)
- Type 类别: 资源记录的类型(如域名到IP地址的转换,主机别名到主机规范名字的转换,邮件服务器别名到邮件服务器规范名字的转换)

注意:NS的Name为子域的名字,而Value为该子域的权威服务器的域名
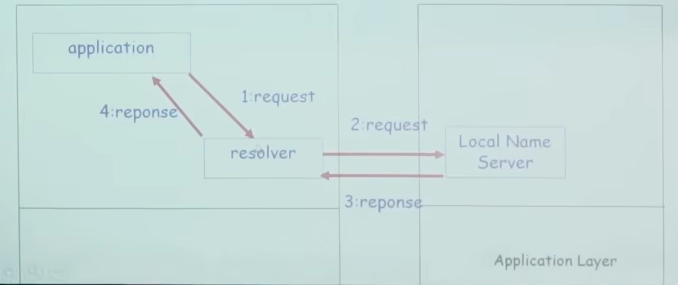
DNS大致工作过程
- 应用调用解析器(resolver)
- 解析器作为客户向Name Server 发出查询报文(封装在UDP段中)
- Name Server返回响应报文(name or ip)
一台设备上网需要4个信息:
- 主机的IP地址
- 所在的子网掩码(通过子网掩码判断目标主机是否在本地子网中)
- defualt gateway(即缺省网关)
- local name server
本地名字服务器(Local Name Server)
- 并不严格属于层次结构
- 每个ISP(居民区的ISP,公司,大学)都有一个本地DNS服务器(也称为默认名字服务器)
- 当一个主机发起一个DNS查询时,查询被送到其本地DNS服务器(起着代理的作用,将查询转发到层次结构中)

查询方式
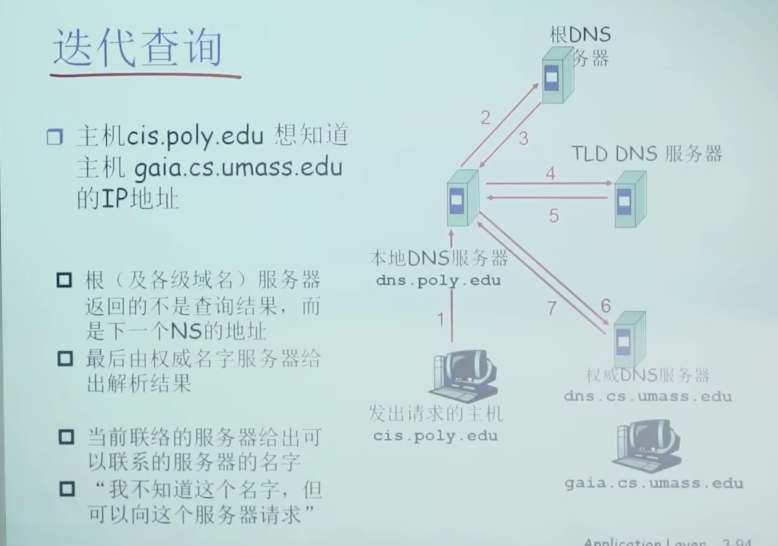
DNS协议,报文

ID号便于处理多个查询(即不需要等上个查询返回结果就可以处理下个查询)


问题3: 维护问题:新增一个域

子域名字—>子域名字服务器的名字—>子域名字服务器的ip地址
攻击DNS

2.6 P2P应用
纯P2P架构
- 没有(或极少)一直运行的服务器
- 任意端系统都可以直接通信
- 利用peer的服务能力
- Peer节点间歇上网,每次IP地址都有可能变化
例子:
- 文件分发(BitTorrent)
- 流媒体(KanKan)
- VoIP(Skype)
文件分发: C/S vs P2P
问题:从一台服务器分发文件(大小F)到N个peer需要多少时间?
Peer节点上下载能力是有限的资源


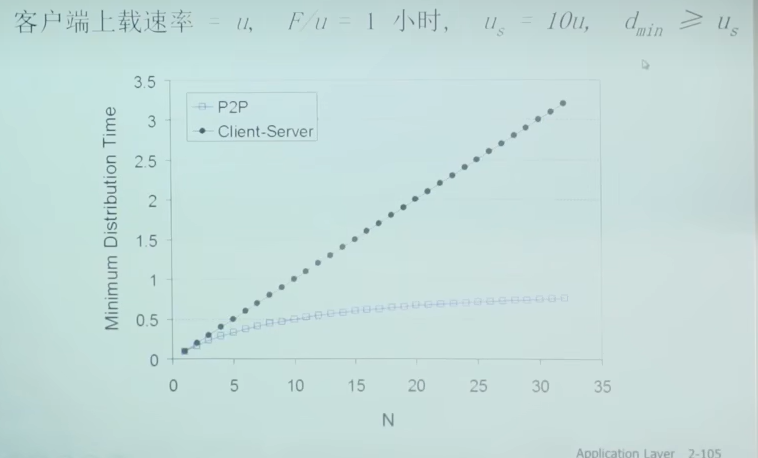
C/S模式,时间随N线性增大
P2P模式,N增加后,时间趋近于一个常数
P2P文件分发
相邻的peer节点之间通过会话关系形成边,形成了覆盖网(overlay)
非结构化P2P
- 其overlay是随机生成的
- 分为三类
- 集中化目录
- 完全分布式
- 混合体
DHT(结构化)P2P(基于分布式散列表)
- 其overlay是有序的,可以形成环,树等关系(更加复杂)

两大问题
- 如何定位所需资源
- 如何处理对等方的加入与离开
可能的方案
- 集中
- 分散
- 半分散
P2P:集中式目录
最初的”Napster”的设计
- 当对等方连接时,它告知中心服务器:
- IP地址
- 内容
- Alice查询”XXX.MP3”
- Alice从Bob处请求文件
- 对等方下线时,告知服务器,不再接受文件请求
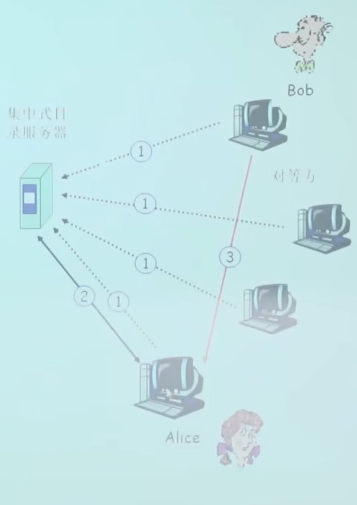
集中式目录存在的问题
- 单点故障(目录服务器故障)
- 性能瓶颈(服务器要维护所有在线的peer节点IP地址和内容)
- 侵犯版权(通过索引,很容易定位到个人)
文件传输是分散的,而定位内容是高度集中的
P2P:完全分布式
泛洪查询:Gnutella
- 全分布式—没有中心服务器
- 随机生成一个overlay
- 开放文件共享协议
- 许多Gnutella客户端实现了Gnutella协议—类似HTTP有许多的浏览器
覆盖网络(overlay):图
- 如果X和Y之间有一个TCP连接,则二者之间存在一条边
- 所有活动的peer节点和边就是覆盖网络
- 边并不是物理链路(逻辑关系)
- 给定一个对等方,通常所连接的节点少于10个
协议
- 在已有的TCP连接上发送查询报文
- 对等方转发查询报文
- 以反方向返回查询命中报文
- 文件传输:HTTP
- 通过TTL限制查询的步数or记住已转发的查询,下次不再转发(防止无止境的查询)
可扩展性:限制范围的泛洪查询(flooding)
对等方加入(如何建立overlay)
- 对等方X必须首先发现一些已在overlay中的其他对等方—使用可用对等方列表
- 自己维持一张对等方列表(经常在线的对等方IP)
- 联系维持列表的Gnutella站点
- X接着试图与该列表上的对等方建立TCP连接,直到与某个对等方Y建立连接
- X向Y发送Ping报文,Y转发该报文
- 所有收到Ping报文的对等方以Pong报文回应(IP地址,共享文件的数量以及总字节数)
- X收到许多Pong报文,然后就能从中随机挑一些节点建立其他TCP连接
如果有些peer节点离开,与其连接的节点可以在选择一些节点进行连接,进而维护overlay
P2P:混合体
利用不匀称性—KaZaA
- 每个对等方要么是一个组长,要么隶属于一个组长
- 对等方与其组长之间有TCP连接
- 组长对之间有TCP连接
- 组长跟踪其所有孩子的内容
- 组长与其他组长联系
- 转发查询到其他组长
- 获得其他组长的数据拷贝

KaZaA:查询
- 每个文件有一个散列标识码和一个描述符
- 客户端向其组长发送关键字查询
- 组长用匹配进行响应
- 对每个匹配:元数据,散列标识码(Hash值)和IP地址
- 如果组长将查询转发给其他组长,其他组长也以匹配进行响应
- 客户端选择要下载的文件
- 向拥有文件的对等方发送一个带散列标识码的HTTP请求
P2P文件分发:BitTorrent
- 文件被分为一个个块256KB,用一个bitmap表示当前节点具有哪些块(比如bitmap第一位为1,第二位为0,则当前节点具有该文件的第一块,不具有第二块)
- 网络中的这些peers发送接受文件块,相互服务
- Torrent(洪流):节点的组,节点之间交换文件块.泛洪时,洪流节点之间交换bitmap
- tracker:跟踪torrent中的参与节点(tracking server维护参与节点,而torrent文件中包含了tracking server的信息)
- Peer加入Torrent:
- 一开始没有块(bitmap全0),但是将会通过其他节点处累积文件块(此时随机请求)
- 向跟踪服务器注册,获得peer节点列表,和部分peer节点构成邻居关系(“连接”)
- 当peer下载时,该peer可以同时向其他节点提供上载服务
- Peer可能会变换用于交换块的peer节点
- 扰动churn:peer节点可能会上线或者下线
- 一旦一个peer拥有整个文件,它会(自私的)离开或者保留(利他主义)在torrent
- 拥有整个文件的节点称为种子
新加入的节点拥有四个以上的块后,优先请求洪流中较稀缺的块(peer节点之间会优先给提供给自己文件块的节点提供文件块—即你对我好,我对你好.优先请求稀缺块一方面使得洪流中稀缺文件块的数量增多,一方面有利于使其他节点向新加入的节点提供文件,对整体个体均有利).为什么不一开始就请求稀缺的块?稀缺的块数量少,较难找到,先随机请求到一些文件块后,就可以向其他节点提供服务,进一步有利于其他节点向自己提供服务
请求块:
- 在任何给定时间,不同peer节点拥有一个文件块的子集
- 周期性的,Alice节点向邻居询问他们拥有哪些块的信息
- Alice向peer节点请求它希望的块,稀缺的块
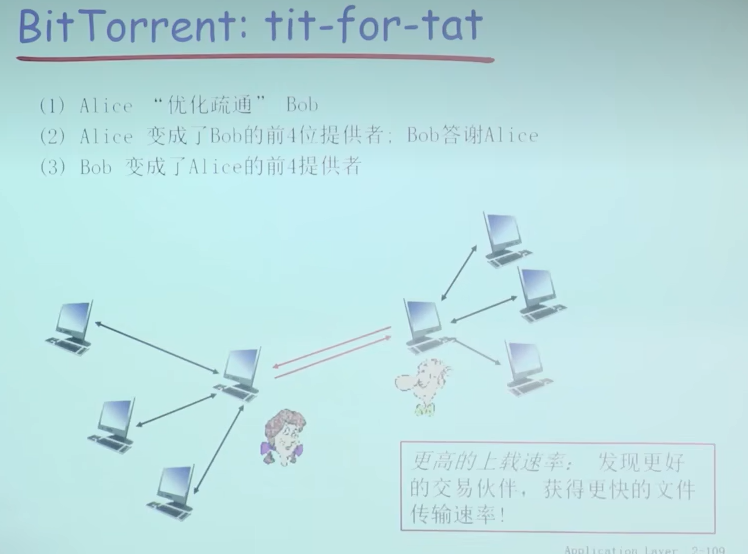
发送块:一报还一报 tit-for-tat
- Alice向4个peer发送块,这些块向它自己提供最大带宽的服务
- 其他peer被Alice阻塞(将不会从Alice处获得服务)
- 每10秒重新评估一次:前4位
- 占2/3周期
- 每个30秒:随机选择其他peer节点,向这个节点发送块
- “优化疏通”这个节点
- 新选择的节点可以加入这个top4
- 占1/3周期
Distributed Hash Table(DHT)
覆盖网络是有序的,故文件块的信息的维护也是有序的,能快速找到拥有文件块的peer节点
- 哈希表
- DHT方案
- 环型DHT以及覆盖网络
- Peer波动
2.7 CDN
视频流化服务和CDN:上下文
视频流量:占据着互联网大部分的带宽
- Netflix,Youtube:占据37%,16%的ISP下行流量
- ~1B Youtube 用户,~75M Netflix 用户
挑战: 规模性-如何服务这~1B用户?
- 单个超级服务器无法提供服务
挑战:异构性
- 不同用户拥有不同的能力(例如: 有线接入和移动用户;带宽丰富和受限用户)
解决方案: 分布式的,应用层面的基础设施(即CDN)
多媒体:视频
视频:固定速度显示的图像序列(eg: 24 images/sec,即24帧)
网络视频特点:
- 高码率:大于音频的十倍甚至九倍,高的网络带宽需求
- 可以被压缩
- 90%以上的网络流量是视频
数字化图像:像素的阵列—每个像素被若干bits表示
编码:使用图像内和图像间的冗余来降低编码的比特数
- 空间冗余(图像内)
- 不是发送N个相同的颜色值,仅发送两个值:颜色和重复的个数N
- 时间冗余(相邻的图像间)
- 不是发送第i+1帧的全部编码,而仅发送和第i帧差别的地方
编码方式:
- CBR(constant bit rate):以固定速率编码
- VBR(variable bit rate):视频编码速率随时间的变化而变化
eg:
- MPEG1 (CD-ROM) 1.5Mbps
- MPEG2 (DVD) 3-6Mbps
- MPEG4 (互联网使用) <1 Mbps
存储视频的流化服务(streaming): DASH
DASH: Dynamic ,Adaptive Streaming over HTTP
服务器:
- 将视频文件分割成多个块
- 每个块独立存储(可以部署在不同服务器中),编码于不同码率(8-10种)
- 告示文件( manifest file):提供不同块的URL
客户端:
- 先获取告示文件
- 周期性地测量服务器到客户端的带宽
- 查询告示文件,在一个时刻请求一个块,HTTP头部指定字节范围
- 如果带宽足够,选择最大码率的视频块
- 会话中的不同时刻,可以切换请求不同的编码块(取决于当时的可用带宽)
“智能”客户端:客户端自适应决定
- 什么时候去请求块(不至于缓存”挨饿”,或者溢出)
- 请求什么编码速率的视频块(当带宽够用时,请求高质量的视频块)
- 哪里去请求块(可以向离自己近的服务器发送URL,或者向高可用带宽的服务器请求)
CDN(Content Distribution Networks)
挑战:服务器如何通过网络向上百万用户同时流化视频内容(上百万视频内容)?
选择1:单个的,大的超级服务中心”mega-server”
- 服务器到客户端路径上跳数较多,瓶颈链路的带宽小导致停顿
- “二八规律”决定了网络同时充斥着同一个视频的多个拷贝,效率低(付费高,带宽浪费,效果差)
- 单点故障点,性能瓶颈
- 周边网络的拥塞
- 简单,但是不可扩展
选项2:通过CDN,全网部署缓存节点,存储服务内容,就近为用户提供服务,提高用户体验
ICP通过购买CDN运营商所提供的CDN服务,进而提高提供的服务质量
- enter deep: 将CDN服务器深入到许多接入网(下层/local ISP)
- 更接近用户,数量多,离用户近,管理困难
- Akamai, 1700 个位置
- bring home:部署在少数(10个左右)关键位置(上层ISP),如将服务器簇安装于POP附件(离若干1st|SP POP较近)
- 采用租用线路将服务器簇连接起来
- Limelight

注意:域名服务器可以完成CDN的重定向
CDN特点:over the top—处于应用层且服务于网络边缘,将主机之间的通信作为一种服务向用户提供
OTT挑战:在拥塞的互联网上复制内容
- 从哪个CDN节点中获取内容?
- 用户在网络拥塞时的行为?
- 在哪些CDN节点中存储什么内容?

CDN:”简单”内容访问场景

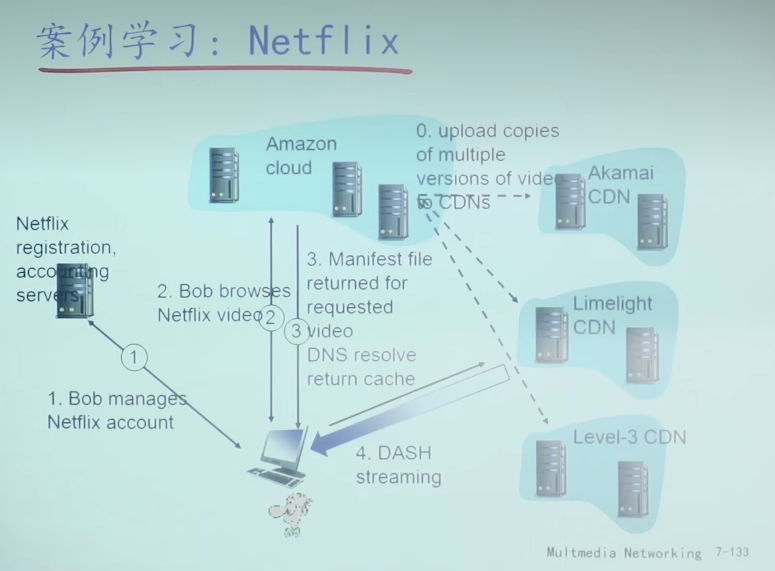
- Bob gets URL for video http://netcinema.com/6Y7B23V from netcinema.com web page:Bob在网页上请求该视频
- resolve http://netcinema.com/6Y7B23V via Bob’s local DNS:浏览器向本地的DNS域名服务器请求该域名的IP地址
- netcinema’s DNS returns URL http://KingCDN.com/NetC6y&B23V :本地DNS服务器请求到netcinema的DNS服务器,netcinema的DNS服务器重定向该域名到KingCDN服务器的域名,让其去找KingCDN的权威域名服务器
- 同5
- Resolve http://KingCDN.com/NetC6y&B23 via KingCDN’s authoritative DNS, which returns IP address of KingCDN server with video(CDN簇选择策略):KingCDN的权威服务器给出,离客户最近的,CDN节点的IP地址
- request video from KingCDN server streamed via HTTP:通过DASH接受视频的流化服务
2.8 TCP套接字编程
Socket编程
应用进程使用传输层提供的服务才能够交换报文,实现应用协议,实现应用
TCP/IP:应用进程使用Socket API访问传输服务
地点:界面上的SAP(Socket)
方式:Socket API
目标:学习如何构建能借助sockets进行通信的C/S应用程序
socket:分布式应用程序之间的门,传输层协议提供的端到端服务接口
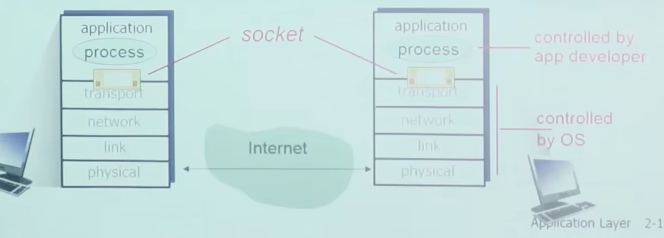
2种传输层服务的socket类型:
- TCP:可靠的,字节流的服务(保证bytestring是有序,无误的,但是不保证报文的界限,所以界限要应用层自己维护)
- UDP:不可靠(UDP数据报)服务
TCP套接字编程
套接字:应用进程与端到端传输协议(TCP或UDP)之间的门户
TCP服务:从一个进程向另一个进程可靠地传输字节流
服务器首先运行,等待连接建立:
1: 服务器进程必须先处于运行状态
- 创建欢迎socket
- 和本地端口捆绑
- 在欢迎socket上阻塞式等待接受用户的连接
3: 当与客户端连接请求到来时
- 服务器接受来自用户端的请求,解除阻塞式等待,返回一个新的socket(与欢迎scket不一样),与客户端通信
- 允许服务器与多个客户端通信
- 使用源IP和源端口来区分不同的客户端
客户端主动和服务器建立连接:
2: 创建客户端本地套接字(隐式捆绑到本地port)
- 指定服务器进程的IP地址和端口号,与服务器进程连接
4: 连接API调用有效时,客户端与服务器建立了TCP连接
从应用程序的角度:TCP在客户端和服务器进程之间提供了可靠的,字节流(管道)服务
C/S模式的应用样例:
- 客户端从标准输入装置读取一行字符,发送给服务端
- 服务器从socket读取字符
- 服务器将字符转换成大写,然后返回给客户端
- 客户端从socket中读取行字符,然后打印出来
数据结构 sockaddr_in
IP地址和port捆版关系的数据结构(标示进程的端节点)
1 | struct sockaddr_in{ |
sin_family:地址簇,表示你用在TCP/IP协议还是其他协议
sin_zero:其他协议地址可能较长,就需要sin_zero来补足
数据结构hostent
1 | struct hostent{ |
作为调用域名解析函数时的参数,返回后,将IP地址(即h_addr)拷贝到sockaddr_in的IP地址部分
h_name:存放主机的域名
h_aliases:主机的一系列别名
h_length:地址的长度
h_addr_list:IP地址的列表,第一个是解析出来的IP地址即h_addr
C/S socket交互: TCP
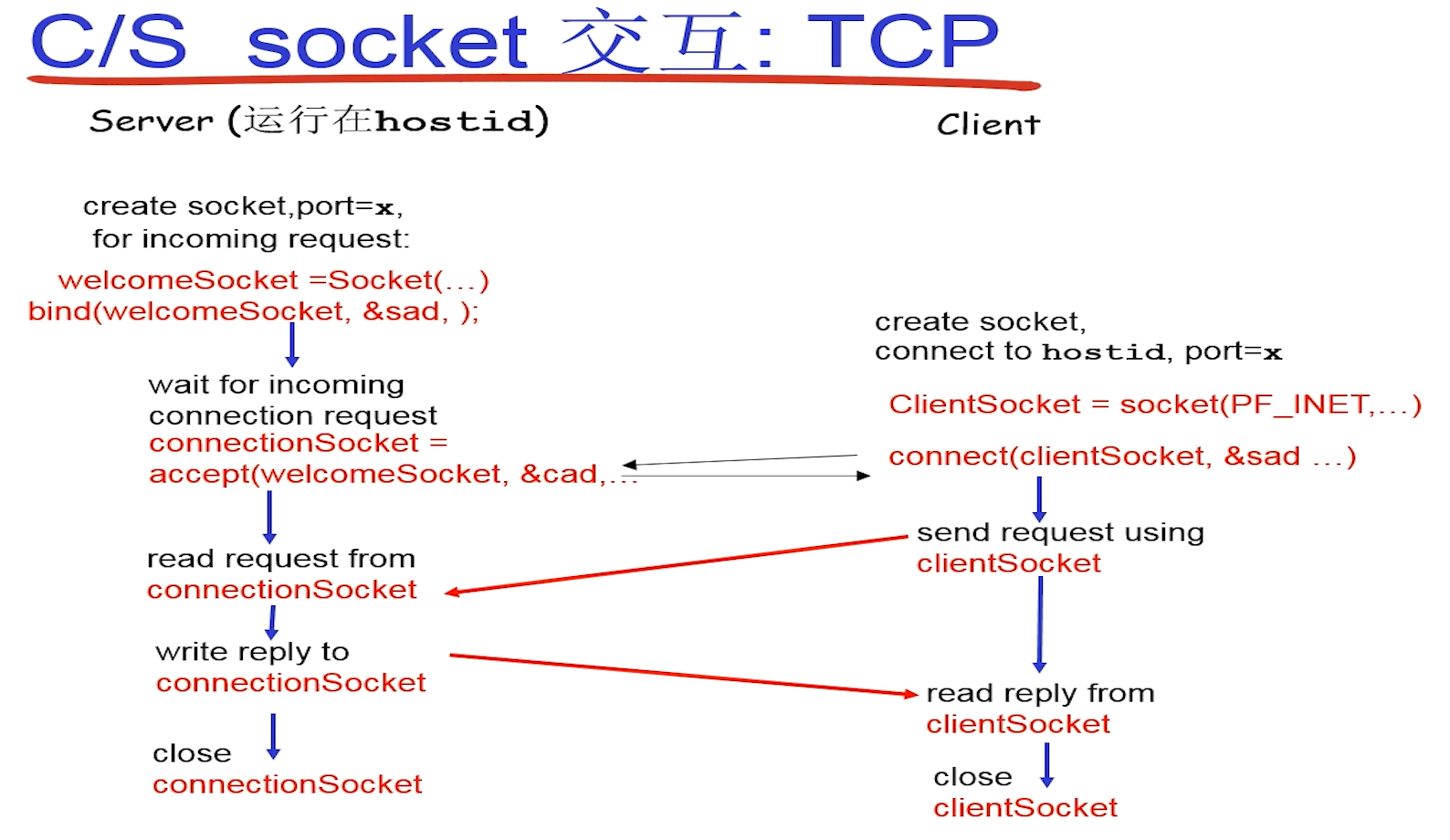
socket()函数可选择参数来生成不同协议的socket(如TCP,UDP)
sad为服务器的IP,port信息,cad为客户端的IP,port信息
服务器的bind函数中sad的数据类型为sockaddr_in,bind将该socket与sad中的本地IP,端口号捆绑
服务器的accept函数中cad用来存储客户端的信息
客户端不需要调用bind—服务器bind是为了指定socket的端口号,以便于客户端连接,而客户端的端口号没有要求,故不用bind(会按照一定的规则给你分配一个没有用的端口)
客户端connect中sad存储的是服务器的IP地址和端口号
例子:C客户端(TCP)


例子:C服务器(TCP)


listen的第二个参数是规定welcome socket的请求队列大小(有多个连接请求,取出第一个后开始执行任务,此时后续的请求都存储在该队列中)
2.9 UDP socket
UDP套接字编程
UDP:在客户端和服务器之间没有连接
- 没有握手
- 发送端在每一个报文中明确地指定目标的IP地址和端口号
- 服务器必须从收到的分组中提取出发送端的IP地址和端口号
UDP:传送的数据可能乱序,也可能丢失
远程视角看UDP服务:UDP为客户端和服务器提供不可靠的字节组的传送服务
UDP的数据单元一般叫datagram(数据报),要注意的是IP协议的数据单元也叫datagram,要根据上下文推断
C/S socket 交互:UDP
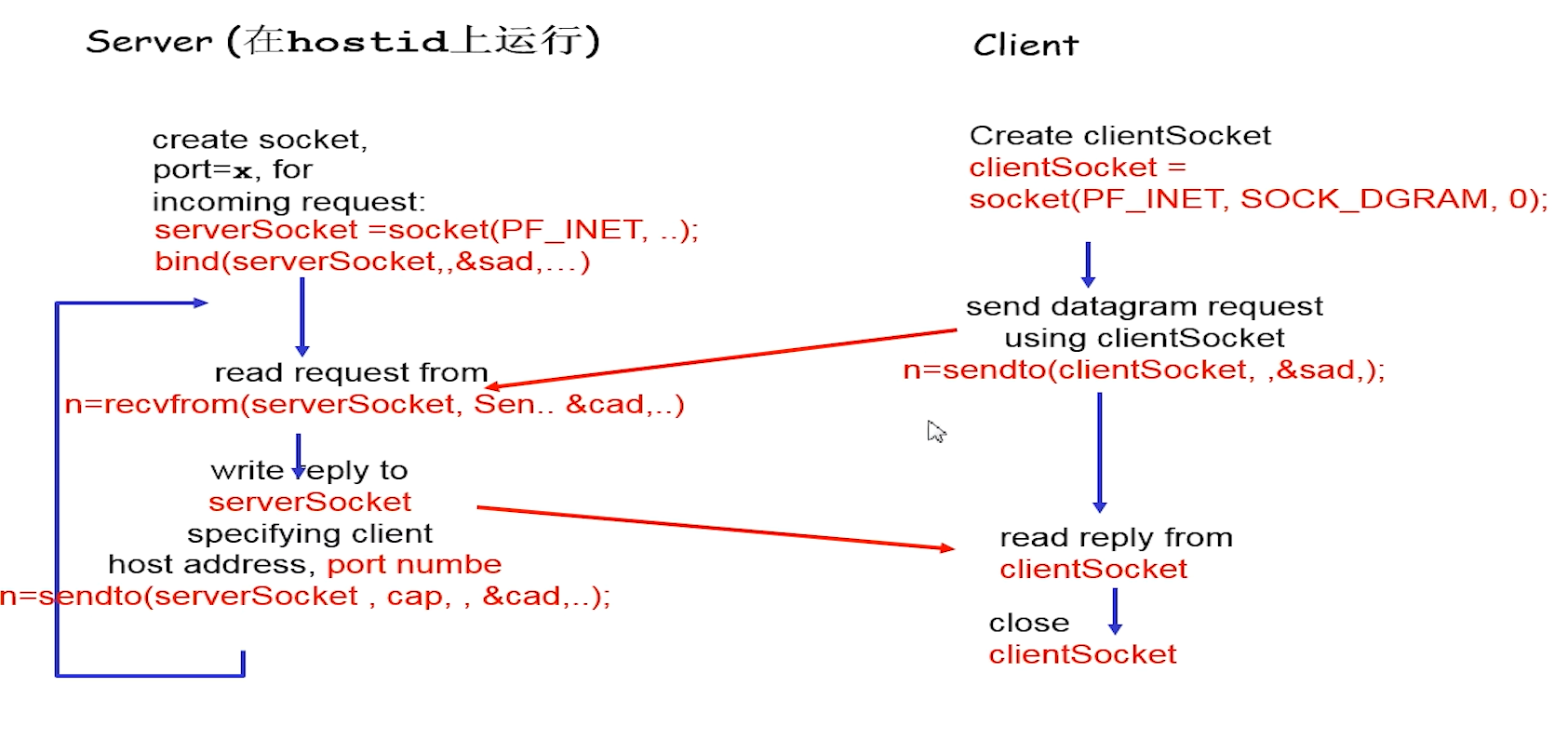
UDP和TCP端口不同,即可占用同一个端口而互不影响
图片上recvfrom的意思是receivefrom
recvfrom若接受到信息,会一直阻塞在该函数
样例:C客户端(UDP)


样例:C服务器(UDP)

